Invited Symposium: Digital Radiology
| INABIS '98 Home Page | Your Session | Symposia & Poster Sessions | Plenary Sessions | Exhibitors' Foyer | Personal Itinerary | New Search |
Materials and Methods
Before describing the Web Server itself, we give a brief overview of the complete PACS. This facilitates understanding how the image data are managed, from acquisition through archival and retrieval. The PACS itself is a distributed network of ``Servers'' dedicated to specific tasks. Each Server is described below in the context of image-flow.
Modality Server
As images are generated from a given scanner, they are transmitted automatically to a specific Modality Server which provides short-term storage on a RAID and transmits copies of the images to various destinations based on pre-defined routing-rules. The destinations include diagnostic review workstations (used by radiologists), clinical review workstations (used by Hospital clinicians), and the Archival Servers (described below). The routing-rules can depend on many different types of parameters related to the study being performed. These typically include the type of study being performed, the imaging modality, and the name of the referring physician. Image transfers to and from the Modality Server (and all other Servers in the PACS) conform to the DICOM standard. One Modality Server is employed per imaging modality (CT, MRI and ultrasound). Each is an IBM PC-compatible computer running the LINUX operating system. DICOM services are provided via a modified version of the Mallinckrodt Institute of Radiology Central Test Node software (see: http://www.erl.wustl.edu/DICOM/ctn.html). (Each Server in the PACS employs the same software and runs the LINUX operating system, including the Web Server.)
Archive Server
There are two Archive Servers in the PACS; one that employs recordable CD technology, and one that employs a digital linear tape (DLT) juke-box. As images are received from each Modality Server, they are grouped by series then recorded automatically to CD (and DLT) for long-term storage.
Retrieval Server
When images are required that are no longer available on one of the Modality Server RAIDs, they must be retrieved from DLT or CD. Retrieval requests are issued automatically (either from a Modality Server or from the Web-Server) when any user tries to access off-line data. Retrieval from the DLT juke-box is automated, whereas retrieval from CD requires human-intervention. Thus, the former is employed whenever possible.
Database Server
In order to account for the images comprising every study handled by the PACS, a ``Master Database'' is employed that resides on a dedicated Server. This database receives input from every other Server in the PACS and keeps track of all patients, studies and series handled, including their location(s) (eg, CD, DLT, or Modality Server). The database is queried most by the Web Server which we describe below.
Web Server
The first incarnation of our ``PACS-browser'' software was developed to run on a dedicated computer using the LINUX operating system and employing the Apache Web Server. Each Modality Server was configured to automatically forward a copy of every image, once received from a scanner, to the Web Server. This process employed the DICOM standard with the Web Server acting a ``provider'' of the Storage Service Class and the transmitting server acting as the ``user''. Each incoming image was stored on the local hard disk in DICOM format and a copy was converted to a JPEG format. A mini-SQL database (see http://www.Hughes.com.au/) residing on the Web Server was subsequently updated to keep track of the images received.
Perl CGI and HTML pages were constructed to provide access to the images. The use of Java was intentionally avoided owing to concerns that the Hospital PCs were inadequately equipped to support it. In order to maintain the confidentiality of patients, each user was required to apply for an account that was enabled after their identity had been verified. User-names and passwords were employed in addition to an underlying system that restricted different users to specific functions depending on their role within our institution and depending on the location from which they logged-in.
The range of functions designed within the PACS-browser included the ability to view images; print images (only on paper); move images (full studies or series) to any DICOM-conformant workstation known to the PACS; download images in DICOM format, or ``pre-fetch'' studies. (Figure 1 illustrates simple image viewing via the PACS-browser.) The latter function was employed to retrieve prior studies of patients undergoing new examinations to allow comparisons to be performed between the old and new studies.
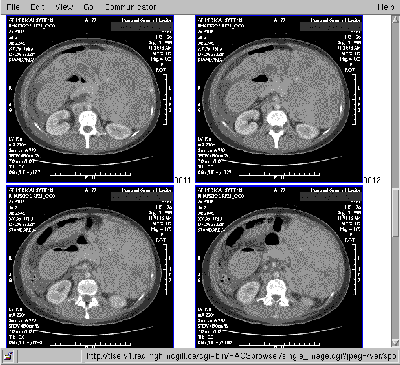 Fig. 1: Images viewed through the PACS-browser may be enlarged or
regenerated with different window width and level settings.
Fig. 1: Images viewed through the PACS-browser may be enlarged or
regenerated with different window width and level settings.
Management of disk space on the Web Server was automated using a first-in-first-out policy with high and low water marks. As data were deleted from disk, the mini-SQL database was updated to reflect the changes. Initially, four 9GB hard disks were employed which was sufficient to hold approximately three weeks of the most recently acquired images. When older images were required, it was necessary to re-transfer them to the Web Server from either a Modality Server (if the data were still on-line) or a Retrieval Server (if the data were off-line). The location of the data was determined through queries to the Master Database residing on the Database Server (described above).
| <= Introduction | MATERIALS & METHODS | Results => |
| Discussion Board | Next Page | Your Symposium |